
스트림
| byte stream | character stream | |
|---|---|---|
| 입력 | InputStream | Reader |
| 출력 | Reader | Writer |
이 클래스들은 모두 추상 클래스이다.
| Input | Output | |
|---|---|---|
| File | FileInputStream FileReader | FileOutputStream FileWriter |
| Memory | ByteArrayInputStream CharArrayReader StringReader | ByteArrayOutputStream CharArrayWriter StringWriter |
| Process | PippedInputStream PippedReader | PippedOutputStream PippedWriter |
파일을 덮어쓰지 않으려면? => boolean append를 파라미터로 받는 메서드 사용
바이너리 파일 vs 텍스트 파일
바이너리 파일
- 기본 텍스트 편집기(메모장, vi 에디터 등)로 편집할 수 없는 파일을 말한다.
- 만약 텍스트 편집기로 변경한 후 저장하면, 파일 포맷이 깨지기 때문에 무효한 파일이 된다.
- 예) .pdf, .ppt, .xls, .gif, .mp3, .jpg, .hwp, .mov, .avi, .exe, .lib 등
바이너리 파일을 편집하려면 해당 파일 포맷을 이해하는 전용 프로그램이 필요하다.
- 바이너리 데이터 읽고 쓰기
- 읽고 쓸 때 중간에서 변환하는 것 없이 바이트 단위로 그대로 읽고 써야 한다.
- InputStream / OutputStream 계열의 클래스를 사용한다.
텍스트 파일
- 기본 텍스트 편집기(메모장, vi 에디터 등)로 편집할 수 있는 파일을 말한다.
- 예) .txt, .csv, .html, .js, .css, .xml, .bat, .c, .py, .php, .docx, .pptx, .xlsx 등
- 텍스트 파일은 전용 에디터가 필요 없다.
텍스트를 편집할 수 있는 에디터라면 편집 후 저장해도 유효하다.
- 텍스트 데이터 읽고 쓰기
- 읽고 쓸 때 중간에서 문자 코드표에 따라 변환하는 것이 필요하다.
- Reader / Writer 계열의 클래스를 사용한다.
Byte Stream
바이트 단위로 출력하기
1) 파일로 데이터를 출력하는 객체를 준비한다.
new FileOutputStream(파일명로)- 지정된 경로에 해당 파일을 자동으로 생성한다.
- 기존에 같은 이름의 파일이 있으면 덮어 쓴다. 기존 파일은 삭제되기 때문에 주의하자.
- 파일 경로가 절대 경로가 아니라면 현재 디렉토리가 기준이 된다.
- Linux, Unix:
/로 시작하지 않으면 - Windows:
c:\,d:\등으로 시작하지 않으면
- Linux, Unix:
2) 1바이트를 출력한다. (write())
- int 값을 아규먼트로 넘기더라도 맨 마지막 1바이트만 출력한다.
3) 출력 도구를 닫는다.
- OS에서 관리하는 자원 중에서 한정된 개수를 갖는 자원에 대해 여러 프로그램이 공유하는 경우, 항상 사용 후 OS에 반납해야 한다. 그래야 다른 프로그램이 해당 자원을 사용할 수 있다.
- ex) 파일, 메모리, 네트워크 연결 등
- 이런 자원을 사용하는 클래스는 보통
java.lang.AutoCloseable인터페이스를 구현하여 자원을 해제시키는close()라는 메서드가 있다.FileOutputStream클래스도 마찬가지이다. - 따라서
FileOutputStream객체를 사용한 후에는close()를 호출하여 사용한 자원을 해제시켜야 한다. close()를 호출하면FileOutputStream이 작업하는 동안 사용했던 모든 자원은 자동으로 해제된다.- 다음의 예제처럼 짧은 시간동안 실행되는 경우,
close()를 호출하지 않아도 자원을 해제시키는 데 문제가 없다. - 문제는 24시간 365일 멈추지 않고 실행하는 서버 프로그램이다. 이 경우 사용한 자원을 즉시 해제시키지 않으면 자원 부족 문제가 발생한다. 우리는 앞으로 자바로 서버 프로그램을 작성할 것이기 때문에 간단한 프로그램을 작성하더라도 close()를 호출하는 것을 습관들여야 한다.
1
2
3
FileOutputStream out = new FileOutputStream("temp/test1.data");
out.write(0x7a6b5c4d); // 출력하는 값은 0x4d
out.close();
바이트 단위로 읽기
1) 파일의 데이터를 읽을 객체를 준비한다.
new FileInputStream(파일경로)- 해당 경로에 파일이 존재하지 않으면 예외가 발생한다.
2) 1바이트를 읽는다.
read()메서드의 리턴 타입이 int라 하더라도 1바이트를 읽어 리턴한다.
3) 읽기 도구를 닫는다.
1
2
3
FileInputStream in = new FileInputStream("temp/test1.data");
int b = in.read(); // 0x4d
in.close();
바이트 배열 출력하기
1
2
3
4
FileOutputStream out = new FileOutputStream("temp/test.data");
byte[] bytes = new byte[] {0x7a, 0x6b, 0x5c, 0x4d, 0x3e, 0x2f, 0x30};
out.write(bytes);
out.close();
바이트 배열의 특정 부분을 출력할 때는 wirte()에 파라미터로 offset과 length 값을 넘겨준다.
1
out.write(bytes, 2, 3); // 2번 데이터부터 3바이트를 출력한다.
바이트 배열 읽기
- 버퍼(buffer): 임시 데이터를 저장하기 위해 만든 바이트 배열
read(버퍼의 주소)- 버퍼가 꽉 찰 때까지 읽는다.
- 버퍼의 크기보다 파일의 데이터가 적으면 파일을 모두 읽어 저장한다.
- 주의! 리턴 값은 읽은 바이트의 개수이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
FileInputStream in = new FileInputStream("temp/test1.data");
// 바이트를 저장할 배열을 넉넉히 준비
byte[] buf = new byte[100];
int count = in.read(buf);
in.close();
System.out.println("읽은 바이트 수: %d\n", count);
for (int i = 0; i < count; i++)
System.out.printf("%x ", buf[i]);
/*
읽은 바이트 수: 7
7a 6b 5c 4d 3e 2f 30
*/
읽은 데이터를 바이트 배열의 특정 위치에 저장하려면 read(버퍼의주소, 저장할위치, 읽을바이트개수)를 사용한다.
1
2
3
4
5
6
7
int count = in.read(buf, 10, 40); // 40바이트를 읽어 10번 방부터 저장한다.
in.close();
System.out.printf("%d\n", count);
for (int i = 0; i < 20; i++)
System.out.printf("%x ", buf[i]);
//7
//0 0 0 0 0 0 0 0 0 0 7a 6b 5c 4d 3e 2f 30 0 0 0
FileInputStrewam 활용: JPEG 파일 읽기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
//1) 파일 정보를 준비한다.
File file = new File("sample/photo1.jpg");
//2) 파일을 읽을 도구를 준비한다.
FileInputStream in = new FileInputStream(file);
// => SOI(Start of Image) Segment 읽기: 2바이트
int b1 = in.read(); // 00 00 00 ff
int b2 = in.read(); // 00 00 00 d8
int soi = b1 << 8 | b2;
// 00 00 00 ff <== b1
// 00 00 ff 00 <== b1 << 8
// | 00 00 00 d8 <== b2
// ------------------
// 00 00 ff d8
System.out.printf("SOI: %x\n", soi);
// => JFIF-APP0 Segment Marker 읽기: 2바이트
int jfifApp0Marker = in.read() << 8 | in.read();
System.out.printf("JFIF APP0 Marker: %x\n", jfifApp0Marker);
// => JFIF-APP0 Length: 2바이트
int jfifApp0Length = in.read() << 8 | in.read();
System.out.printf("JFIF APP0 정보 길이: %d\n", jfifApp0Length);
byte[] jfifApp0Info = new byte[jfifApp0Length];
in.read(jfifApp0Info);
// => JFIF-APP0 Length: 5바이트
String jfifApp0Id = new String(jfiApp0Info, 0, 4);
System.out.printf("JFIF App ID: %s\n", jfifApp0Id);
// SOF0(Start of Frame) 정보 읽기
// - 그림 이미지의 크기 및 샘플링에 관한 정보를 보관하고 있다.
// - 0xFFC0 ~ 0xFFC2 로 표시한다.
// => SOF Marker 찾기
int b;
while (true) {
b = in.read();
if (b == -1)
break;
if (b == 0xFF) {
b = in.read();
if (b == -1)
break;
if (b >= 0xC0 && b <= 0xC2)
break;
}
}
if (b == -1) {
System.out.prinln("유효한 JPEG 파일이 아닙니다.");
return;
}
// => SOF Length 읽기: 2바이트
int sofLength = in.read() << 9 | in.read();
System.out.printf("%SOF 데이터 크기: %d\n", sofLength);
// => SOF 데이터 읽기: 17바이트 (위에서 알아낸 크기)
byte[] sofData = new byte[sofLength];
in.read(sofData);
// => SOF 샘플링 정밀도: 1바이트
System.out.printf("SOF 샘플링 정밀도: %s\n", sofData[0]);
// => SOF 이미지 높이: 2바이트
int height = ((sofData[1] << 8) & 0xff00) | (sofData[2] & 0xff);
// => SOF 이미지 너비: 2바이트
int width = ((softData[3] << 8) & 0xff00) || (softData[4] & 0xff));
System.out.printf("SOF 이미지 크기(w x h): %d x %d\n", width, height);
in.close();
텍스트 출력하기
String 객체의 데이터를 출력하려면 문자열을 담은 byte[] 배열을 리턴 받아야 한다.
String.getBytes()
- 특정 인코딩을 지정하지 않고 그냥 바이트 배열을 달라고 하면, String 클래스는 JVM 환경 변수 ‘file.encoding’에 설정된 문자집합으로 바이트 배열을 인코딩한다.
- 이클립스에서 애플리케이션을 실행할 때 다음과 같이 JVM 환경변수를 자동으로 붙인다(
$ java -Dfile.encoding=UTF-8...) 그래서getBytes()가 리턴한 바이트 배열의 인코딩은 UTF-8이 되는 것이다. - 만약 이 예제를 이클립스가 아니라 콘솔창에서
-Dfile.encoding=UTF-8옵션 없이 실행한다면,getBytes()가 리턴하는 바이트 배열은 OS의 기본 인코딩으로 변환될 것이다.- Windows => MS949
- Linux => UTF-8
- OS에 상관 없이 동일한 실행 결과를 얻고 싶다면
- file.encoding 옵션 붙이기:
java -Dfile.encoding=UTF-8 -cp bin/main... getBytes()호출할 때 인코딩할 문자 집합을 지정하기:str.getBytes("UTF-8")
- file.encoding 옵션 붙이기:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
String str = new String("AB가각");
System.out.printf("file.encoding=%s\n", System.getProperty("file.encoding"));
// 1. 인코딩 지정X
byte[] bytes1 = str.getBytes();
// 이클립스: UCS2 => UTF-8
// Windows: UCS2 => MS949
// Linux: UCS2 => UTF-8
// macOS: UCS2 => UTF-8
for (byte b : bytes1) System.out.printf("%x ", b);
// (이클립스) 41 42 ea b0 80 ea b0 81
FileOutputStream out1 = new FileOutputStream("temp/utf.txt");
out1.write(bytes);
// 2. MS949로 인코딩하기
byte[] bytes2 = str.getBytes("MS949");; // UCS2 ==> MS949
for (byte b : bytes2) System.out.printf("%x ", b)
// 41 42 b0 a1 b0 a2
FileOutputStream out2 = new FileOutputStream("temp/ms949.txt");
out2.write(bytes2);
// 3. UTF-16BE로 인코딩하기
byte[] bytes3 = str.getBytes("UTF-16BE"); // UCS2 ==> UTF-16BE
for (byte b : bytes3) System.out.printf("%x ", b);
// 0 41 0 42 ac 0 ac 1
FileOutputStream out3 = new FileOutputStream("temp/utf16be.txt");
out3.write(bytes3);
// 4. UTF-16LE로 인코딩하기
byte[] bytes4 = str.getBytes("UTF-16LE"); // UCS2 ==> UTF-16LE
for (byte b : bytes4) System.out.printf("%x ", b);
// 41 0 42 0 0 ac 1 ac
FileOutputStream out4 = new FileOutputStream("temp/utf16le.txt");
out4.write(bytes4);
// 5. UTF-8로 인코딩하기
byte[] bytes5 = str.getBytes("UTF-8"); // UCS2 ==> UTF-8
for (byte b : bytes5) System.out.printf("%x ", b);
// 41 42 ea b0 80 ea b0 81
FileOutputStream out5 = new FileOutputStream("temp/utf8.txt");
out4.write(bytes5);
텍스트 데이터 읽기
파일의 각 문자를 읽기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
StringBuffer strbuf = new StringBuffer();
FileInputStream in = new FileInputStream("sample/ms949");
// 'A' 문자 읽기
int b = in.read(); // 1 byte 읽기
// 'B' 문자 읽기
b = in.read();
// '가' 문자 읽기
b = in.read() << 8 | in.read(); // 2byte 읽기
// '각' 문자 읽기
b = in.read() << 8 | in.read(); // 2byte 읽기
파일의 데이터를 한 번에 읽어오자.
바이트가 어떤 문자 집합으로 인코딩 되었는지 알려주지 않는다면, String 객체를 생성할 때 JVM 환경 변수 file.encoding 에 설정된 문자집합으로 가정하고 UCS2 문자 코드로 변환한다.
다음의 코드는 utf-8 파일을 읽는 코드인데, 실행 환경에 따라 문자 변환의 결과가 달라진다.
1
2
3
4
5
6
7
8
9
10
11
12
13
// JVM 환경변수 file.encoding 값
System.out.printf("file.encoding=%s\n", System.getProperty("file.encoding"));
FileInputStream in = new FileInputStream("sample/utf8.txt");
// 파일의 데이터를 한 번에 읽어오자.
byte[] buf = new byte[1000];
int count = in.read(buf);// <= 41 42 ea b0 80 ea b0 81 (AB가각)
in.close();
// 읽은 바이트를 String 객체로 만들어보자.
String str = new String(buf, 0, count); //=> 바이트가 어떤 문자 집합으로 되었는지 알려주지 않는다면?
System.out.println(str);
- 이클립스에서 실행: 성공
- JVM 실행 옵션에
-Dfile.encoding=UTF-8환경 변수가 자동으로 붙는다. 그래서 String 클래스는 바이트 배열의 값을 UCS2로 바꿀 때 UTF-8 문자표를 사용하여 UCS2로 변환한다. - utf8.txt => 41 42 ea b0 80 ea b0 81
- UCS2 => 0041 0042 ac00 ac01 <== 정상적으로 바뀐다.
- JVM 실행 옵션에
- Windows 콘솔에서 실행: 실패
- JVM을 실행할 때 file.encoding을 설정하지 않으면 OS의 기본 문자집합으로 설정한다.
- Windows의 기본 문자집합은 MS949이므로 file.encoding 값도 MS949로 설정된다.
- 바이트 배열은 UTF-8로 인코딩 되었는데, MS949 문자표를 사용하여 UCS2로 변환하려 하니까 잘못된 문자로 변환되는 것이다.
- 해결책: JVM을 실행할 때 file.encoding 옵션에 정확하게 해당 파일의 인코딩을 설정해야 한다. 즉 utf-8.txt 파일은 utf-8로 인코딩 되었기 때문에
-Dfile.encoding=UTF-8옵션을 붙여서 실행해야 UCS2로 정산 변환된다.
- Linux/macOS 콘솔에서 실행: 성공
- Linux와 macOS의 기본 문자 집합은 UTF-8이다.
- 따라서 JVM을 실행할 때 file.encoding 옵션에 정확하게 해당 파일의 인코딩을 지정하지 않아도 해당 파일을 UTF-8 문자로 간주하여 UTF-8 문자표에 따라 UCS2로 변환한다.
다음의 코드는 MS949 파일을 읽는 코드인데, 실행 환경에 따라 문자 변환의 결과가 달라진다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// JVM 환경변수 file.encoding 값
System.out.printf("file.encoding=%s\n", System.getProperty("file.encoding"));
FileInputStream in = new FileInputStream("sample/ms949.txt");
// 파일의 데이터를 한 번에 읽어오자.
byte[] buf = new byte[1000];
int count = in.read(buf);
in.close();
// 읽은 바이트를 String 객체로 만들어보자.
String str = new String(buf, 0, count); //=> 바이트가 어떤 문자 집합으로 되었는지 알려주지 않는다면?
System.out.println(str);
// MS949 코드를 UTF-8 문자로 가정하고 다룰 때 한글이 깨지는 원리!
// - ms949.txt
// => 01000001 01000010 10110000 10100001 10110000 10100010 = 41 42 b0 a1 b0 a2
// - MS949 코드를 변환할 때 UTF-8 문자표를 사용하면 다음과 같이 잘못된 변환을 수행한다.
// byte(UTF-8) => char(UCS2)
// 01000001 -> 00000000 01000001 (00 41) = 'A' <-- 정상적으로 변환되었음.
// 01000010 -> 00000000 01000010 (00 42) = 'B' <-- 정상적으로 변환되었음.
// 10110000 -> 꽝 (xx xx) <-- 해당 바이트가 UTF-8 코드 값이 아니기 때문에 UCS2로 변환할 수 없다.
// 10100001 -> 꽝 (xx xx) <-- 그래서 꽝을 의미하는 특정 코드 값이 들어 갈 것이다.
// 10110000 -> 꽝 (xx xx) <-- 그 코드 값을 문자로 출력하면 => �
// 10100010 -> 꽝 (xx xx)
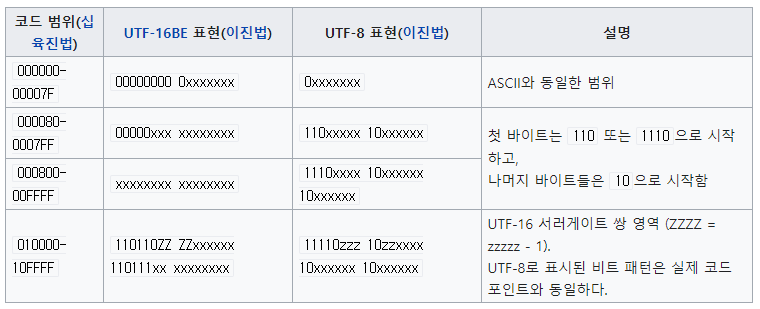
위의 표에서 MS949로 표현된 한글(예: 10110000)은 UTF-8표현에서 찾을 수 없다. 영어 문자의 경우 (ex: 01000001) UTF-8에서 첫 번째 줄과 일치하기 때문에 UTF-16BE로 바꿀 수 있다. 따라서 MS949 코드를 UTF-8 문자로 가정하고 다룰 때 영어는 잘 나오지만 한글이 깨지는 것이다.
- 이클립스에서 실행: 실패
- 이클립스에서 JVM을 실행할 때
-Dfile.encoding=UTF-8옵션을 붙인다. - 따라서 String 클래스는 바이트 배열의 값을 UCS2로 변환할 때 UTF-8 문자표를 사용한다.
- 바이트 배열의 값이 MS949이기 때문에 MS949 문자표로 변환하면 UCS2 문자 코드로 잘 변환되는 것이다.
- 이클립스에서 JVM을 실행할 때
- Windows 콘솔에서 실행: 성공
- JVM을 실행할 때
file.encoding환경 변수를 지정하지 않으면 OS의 기본 문자집합으로 설정한다. - Windows의 기본 문자 집합은 MS949이기 때문에 file.encoding 값은 MS949로 설정된다.
- 바이트 배열의 값이 MS949이기 때문에 MS949 문자표로 변환하면 UCS2 문자 코드로 잘 변환되는 것이다.
JVM 환경 변수 file.encoding에 설정된 문자표에 상관 없이 String 객체를 만들 때 바이트 배열의 인코딩 문자 집합을 정확하게 알려준다면, UCS2 코드 값으로 정확하게 변환해줄 것이다.
1
2
3
4
5
6
7
8
9
10
System.out.printf("file.encoding=%s\n", System.getProperty("file.encoding")); // UTF-8
FileInputStream in = new FileInputStream("sample/utf16le.txt");
byte[] buf = new byte[100];
int count = in.read(buf);
in.close();
String str = new String(buf, 0, count, "UTF-16LE");
System.out.println(str);
Character Stream
문자 단위로 출력하기
배경: JVM의 문자열을 파일로 출력할 때 바이트 스트림 클래스를 사용하면 문자집합을 지정해야 하는 번거로움이 있다. 이런 번거로움을 해결하기 위해 문자 스트림 클래스인 Reader/Writer 계열의 클래스가 등장했다.
- 문자 단위로 출력할 도구 준비
FileWriter out = new FileWriter("temp/test2.txt");
- 문자 출력하기
- 자바는 문자 데이터를 다룰 때 UCS2(2 byte) 유니코드를 사용한다.
- 그래서 출력할 때 UCS2 유니코드 값을 JVM에 설정된 기본 문자코드표의 값으로 변환하여 출력한다.
- JVM을 실행할 때 출력 데이터의 문자 코드표를 지정하지 않으면 OS의 기본 문자코드표에 따라 변환한다.
- Windows OS(MS949), Unix(UTF-8)
- JVM을 실행할 때 출력 데이터의 문자 코드표를 지정하는 방법
java -Dfile.encoding=문자코드표 -cp 클래스경로 클래스명
- 이클립스에서 실행
- JVM을 실행할 때
-Dfile.encoding=UTF-8옵션을 자동으로 붙인다. - 그래서 출력할 때, UCS2를 UTF-8 코드로 변환하여 파일에 쓴다.
- JVM을 실행할 때
- 콘솔창에서 실행
- file.encoding 환경 변수를 지정하지 않으면, OS가 기본으로 사용하는 문자 코드로 변환하여 파일에 쓴다. (Windows: MS949, Unix: UTF-8)
- JVM을 실행할 때
-Dfile.encoding=문자코드표옵션을 지정한다면, 해당 옵션에 지정된 문자 코드로 변환하여 파일에 쓴다.
- 결론
- OS에 영향 받지 않으려면, JVM을 실행할 때 반드시 file.encoding JVM 환경 변수를 설정한다.
- 문자 집합은 국제 표준인 UTF-8을 사용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
// character stream - 문자 단위로 출력하기
package com.eomcs.io.ex03;
import java.io.FileWriter;
public class Exam0110 {
public static void main(String[] args) throws Exception {
// 1) 문자 단위로 출력할 도구 준비
FileWriter out = new FileWriter("temp/test2.txt");
// 현재 JVM 환경 변수 'file.encoding' 값 알아내기
System.out.printf("file.encoding=%s\n", System.getProperty("file.encoding"));
// => 이 예제를 이클립스에서 실행한다면,
// 앞의 2바이트는 버리고,
// 뒤의 2바이트(UCS2)를 UTF-8 코드표에 따라
// 1 ~ 4 바이트 값으로 변환하여 파일에 쓴다.
// => 즉 이클립스에서 자바 프로그램을 실행할 때
// -Dfile.encoding=UTF-8 옵션을 붙여 실행하기 때문이다.
// => OS의 기본 문자표로 출력하고 싶다면,
// 콘솔창에서 위 옵션 없이 직접 이 클래스를 실행하라.
//
// UCS2에서 한글 '가'는 ac00이다.
out.write(0x7a6bac00);
// - 앞의 2바이트(7a6b)는 버린다.
// - 뒤의 2바이트(ac00)은 UTF-8(eab080) 코드 값으로 변환되어 파일에 출력된다.
// UCS2에서 영어 A는 0041이다.
// 출력하면, UTF-8 코드 값(41)이 파일에 출력된다.
out.write(0x7a5f0041); //
// - 앞의 2바이트(7a5f)는 버린다.
// - 뒤의 2바이트는 UTF-8(41) 코드 값으로 변환되어 파일에 출력된다.
out.close();
System.out.println("출력 완료!");
}
}
문자 단위로 읽기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// 1) 파일의 데이터를 읽을 객체를 준비한다.
FileReader in = new FileReader("sample/ms949.txt"); // 41 42 b0 a1 b0 a2
// 2) 출력 스트림 객체를 생성할 때 파일의 문자 집합을 지정하지 않으면,
// JVM 환경 변수 'file.encoding'에 설정된 문자코드표에 따라
// 바이트를 읽어서 UCS2로 바꾼 후에 리턴한다.
// 현재 JVM 환경 변수 'file.encoding' 값 알아내기
System.out.printf("file.encoding=%s\n", System.getProperty("file.encoding"));
// file.encoding이 UTF-8로 되어 있다면,
// => 영어는 1바이를 읽어서 2바이트 UCS2로 변환한다.
// => MS949도 영어인 경우 UTF-8과 같기 때문에 변환하는데 문제가 없다.
int ch1 = in.read(); // 41 => 0041('A')
int ch2 = in.read(); // 42 => 0042('B')
// => 한글은 MS949와 UTF-8이 다르다.
// MS949로 인코딩 된 것을 UTF-8로 간주하여 변환한다면,
// UTF-8 문자가 아니기 때문에
// 다음과 같이 잘못되었다는 의미로 특정 값(fffd)으로 변환한다.
int ch3 = in.read(); // b0 a1 => fffd => �
int ch4 = in.read(); // b0 a2 => fffd => �
// 3) 읽기 도구를 닫는다.
in.close();
System.out.printf("%x, %x, %x, %x\n", ch1, ch2, ch3, ch4);
문자 배열 출력하기
FileOutputStream은 byte[] 을 출력하지만, FileWriter는 char[]을 출력한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
FileWriter out = new FileWriter("temp/test2.txt");
char[] chars = new char[] {'A', 'B', 'C', '가', '각', '간', '똘', '똥'};
out.write(chars); // 문자 배열 전체를 출력한다.
// 당연히 UCS2를 JVM 환경 변수 'file.encoding'에 설정된 문자 코드표에 따라 변환하여 출력한다.
// JVM이 입출력 문자 코드표로 UTF-8을 사용한다면
// 영어는 1바이트로 변환되어 출력될 것이고,
// 한글은 3바이트로 변환되어 출력될 것이다.
// JVM(UCS2) File(UTF-8)
// 00 41 ==> 41
// 00 42 ==> 42
// 00 43 ==> 43
// ac 00 ==> ea b0 80
// ac 01 ==> ea b0 81
// ac 04 ==> ea b0 84
// b6 18 ==> eb 98 98
// b6 25 ==> eb 98 a5
out.close();
문자 배열의 특정 부분을 출력하기 위해서는 wirte() 메서드에 index과 length 값을 설정한다.
1
2
3
4
5
FileWriter out = new FileWriter("temp/test2.txt");
char[] chars = new char[] {'A','B','C','가','각','간','똘','똥'};
out.write(chars, 2, 3); // 2번 문자부터 3 개의 문자를 출력한다.
out.close();
System.out.println("데이터 출력 완료!");
문자 배열 읽기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
FileReader in = new FileReader("temp/test2.txt");
char[] buf = new char[100];
// read(버퍼의주소)
// => 버퍼가 꽉 찰 때까지 읽는다.
// => 물론 버퍼 크기보다 파일의 데이터가 적으면 파일을 모두 읽어 버퍼에 저장한다.
// => 리턴 값은 읽은 문자의 개수이다. 바이트의 개수가 아니다!!!!!
// FileInputStream.read()의 리턴 값은 읽은 바이트의 개수였다.
// => 파일을 읽을 때 JVM 환경 변수 'file.encoding'에 설정된 문자코드표에 따라 바이트를 읽는다.
// 그리고 2바이트 UCS2 코드 값으로 변환하여 리턴한다.
// => JVM의 문자코드표가 UTF-8이라면,
// 파일을 읽을 때, 영어나 숫자, 특수기호는 1바이트를 읽어 UCS2으로 변환할 것이고
// 한글은 3바이트를 읽어 UCS2으로 변환할 것이다.
int count = in.read(buf);
// File(UTF-8) JVM(UCS2)
// 41 ==> 00 41
// 42 ==> 00 42
// 43 ==> 00 43
// ea b0 80 ==> ac 00
// ea b0 81 ==> ac 01
// ea b0 84 ==> ac 04
// eb 98 98 ==> b6 18
// eb 98 a5 ==> b6 25
in.close();
System.out.printf("%d\n", count);
for (int i = 0; i < count; i++)
System.out.printf("%c(%x)\n", buf[i], (int)buf[i]);
System.out.println();
읽은 데이터를 문자 배열의 특정 위치에 저장하기 위해서는 read(버퍼의주소, 저장할위치, 읽을바이트개수) 메서드를 사용한다. 이때 리턴 값은 실제 읽은 문자의 개수이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
FileReader in = new FileReader("temp/test2.txt");
char[] buf = new char[100];
// read(버퍼의주소, 저장할위치, 읽을바이트개수)
// => 리턴 값은 실제 읽은 문자의 개수이다.
int count = in.read(buf, 10, 40); // 40개의 문자를 읽어 10번 방부터 저장한다.
in.close();
System.out.printf("%d\n", count);
for (int i = 0; i < 20; i++)
System.out.printf("%c(%x) ", buf[i], (int) buf[i]);
System.out.println();