
복습
- stateful
- 스레드를 덜 생산하고 삭제한다. 따라서 가비지가 덜 생긴다
- 많은 클라이언트에 연결할 수 없다.
- stateless
- 클라이언트가 요청할 때 스레드를 생성해서 응답하면 스레드를 즉시 삭제
- 가비지가 많이 생성된다.
- stateless + thread pool
- 가비지를 줄인다
- 인스턴스 생성 시간을 줄인다.
스레드풀
v36. 스레드풀 구현
스레드풀
- 스레드를 풀링 기법(pooling)을 이용하여 관리한다.
- 스레드를 사용한 후에 버리지 않고 재사용하여 가비지 생성을 줄인다.
풀링 기법(pooling)
- 사용한 객체를 버리지 않고 보관해 두었다가 재사용하는 객체 관리 기법이다.
- 동일한 객체를 자주 생성하고, 생성한 객체를 쓰고 버리는 상황에서 대량이 가비지가 생성되는 경우에 적합하다.
- GoF의 디자인 패턴에서 Flyweight 패턴의 한 예이다.
1단계: 스레드풀을 정의한다.
com.eomcs.util.concurrent.ThreadPool추가- 스레드 + 작업을 맡기고 + 깨우는 기능 + 작업 완료 후 잠자는 기능
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
public class ThreadPool {
// 스레드풀의 종료 상태
boolean stopping = false;
List<Worker> workers = new ArrayList<>();
// 스레드 + 작업을 맡기고 + 깨우는 기능 + 작업 완료 후 잠자는 기능
class Worker extends Thread {
Runnable task;
public void setTask(Runnable task) {
// 스레드가 할 작업을 배정한 후
this.task = task;
synchronized (this) {
// 스레드를 깨운다.
this.notify();
}
}
@Override
public void run() {
synchronized (this) {
while (true) {
try {
System.out.printf("[%s] - 스레드 대기 중...\n", this.getName());
this.wait();
if (ThreadPool.this.stopping) { // 스레드풀이 종료 상태라면,
// 스레드는 깨어나는 즉시 실행을 멈춘다.
break;
}
System.out.printf("[%s] - 스레드 작업 시작!\n", this.getName());
// 이 스레드 객체에 대해 대기 상태로 있다가
// 이 스레드에게 깨어나라는 알림(notify()/nofifyAll())이 온다면
// 즉시 running 상태로 되돌아 간다.
} catch (Exception e) {
System.out.printf("[%s] - 스레드 실행 중 오류 발생!\n", this.getName());
break;
// 기다리다가 인터럽트 예외가 발생하면
// 스레드를 종료한다.
}
try {
task.run();
System.out.printf("[%s] - 스레드 작업 종료!\n", this.getName());
} catch (Exception e) {
System.out.printf("[%s] - %s\n",
this.getName(), e.getMessage());
// 작업 수행 중 오류가 발생하더라도
// 스레드는 계속 유효하다.
} finally {
// 정상적인 종료든 작업 수행 중 예외가 발생했든 간에
// 작업을 마친 스레드는 재사용할 수 있도록
// 다시 목록에 보관되어야 한다.
workers.add(this);
System.out.printf("[%s] - 스레드풀로 되돌아 감!\n", this.getName());
}
}
}
}
}
public void execute(Runnable task) {
if (stopping) {
throw new RuntimeException("스레드풀이 종료 상태입니다!");
}
Worker t;
if (workers.size() == 0) {
// 스레드가 없다면 새로 생성한다.
t = new Worker();
System.out.printf("[%s] - 스레드 생성!\n", t.getName());
// 그리고 즉시 실행한다.
// - 실행하더라도 스레드는 처음에 스스로 대기 상태로 갈 것이다.
t.start();
// 현재 main 스레드를 잠깐 멈추게 하여
// 새로 만든 스레드가 실행할 틈을 주자!
// 그래야만 새로 만든 스레드가 실행하자 마자 대기상태로 간다.
try {
Thread.sleep(20);
} catch (Exception e) {
// sleep() 중 발생한 예외는 무시한다.
}
} else {
// 스레드가 있다면, 스레드풀에서 한 개 꺼낸다.
// - 스레드풀에서 꺼낸 스레드는 현재 대기 상태이다.
t = workers.remove(0);
System.out.printf("[%s] - 스레드 꺼내서 재사용!\n", t.getName());
}
// 스레드를 깨워서 일을 시킨다.
// - 스레드에게 해야 할 작업을 배정하면 된다.
t.setTask(task);
}
public void shutdown() {
try {
this.stopping = true;
while (!workers.isEmpty()) { // 스레드풀에 대기 중인 스레드가 있다면,
Worker worker = workers.remove(0); // 맨 앞에 있는 스레드를 꺼내서
synchronized (worker) {
worker.notify(); // 스레드를 깨운다.
// 스레드는 깨어나면 stopping 상태에 따라 종료 여부를 결정하도록 프로그래밍 되어 있다.
// => Worker 스레드를 코드를 보라!
}
}
// 스레드풀에서 대기하지 않고 현재 작업을 수행하는 스레드가 있을 수 있다.
// 그 스레드가 작업을 끝낼 때까지 좀 기다리자.
Thread.sleep(2000);
// 다시 한 번 대기하고 있는 스레드를 종료해 보자!
while (!workers.isEmpty()) { // 스레드풀에 대기 중인 스레드가 있다면,
Worker worker = workers.remove(0); // 맨 앞에 있는 스레드를 꺼내서
synchronized (worker) {
worker.notify(); // 스레드를 깨운다.
// 스레드는 깨어나면 stopping 상태에 따라 종료 여부를 결정하도록 프로그래밍 되어 있다.
// => Worker 스레드를 코드를 보라!
}
}
} catch (Exception e) {
System.out.println("스레드풀을 종료하는 중에 예외 발생!");
e.printStackTrace();
}
}
}
ThreadPool.worker.run()
wait()에서 인터럽트 예외가 발생할 수 있고, run()에서 런타임 예외도 발생할 수 있다. 예외 처리를 따로 할 수도 있고 한꺼번에 묶어서 할 수도 있지만 , 여기서는 따로 처리해주었다. 따로 처리해줄 경우 run() 메서드 중 예외가 발생해도 해당 작업만 취소하고 스레드 자체는 유효하다. 예외를 한꺼번에 처리할 경우 run()에서 예외가 발생했을 때 전체 작업이 종료되어야 한다. 한편 wait()`에서 인터럽트 예외가 발생하면 스레드를 종료시키도록 하자.
ThreadPool.execute()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public void execute(Runnable task) {
Worker t;
if (workers.size() == 0) {
t = new Worker();
System.out.printf("[%s] - 스레드 생성!\n", t.getName());
t.start();
try {
Thread.sleep(20);
} catch (Exception e) {
}
} else {
t = workers.remove(0);
System.out.printf("[%s] - 스레드 꺼내서 재사용!\n", t.getName());
}
t.setTask(task);
}
위의 코드에서 Thread.sleep(500)을 하는 이유는 main 스레드를 잠간 멈추게 해서 새로 만든 스레드가 실행할 틈을 주는 것이다. 그래야만 새로 만든 스레드가 실행하자마자 대기상태로 간다.
만약 이렇게 틈을 주지 않으면, 스레드가 실행하기도 전에 운영체제가 CPU를 메인 스레드에게 줘서 다음 코드인 t.setTask(task)를 먼저 실행해버린다. 그러면 아직 스레드가 기다리지도 않는데 (this.wait() 실행 안되었음) 깨어나라고(notify()) 명령하기 때문에 프로그램이 제대로 실행되지 않는다.
물론 운영체제가 CPU를 생성된 스레드에게 주고 wait()까지 실행한 다음에 메인 스레드에게 CPU를 줄 수도 있다. 그러나 이것은 CPU 스케줄링에 따른 것으로 어떨 때는 실행이 잘 되고, 어떨 때는 실행이 잘 안 될 수 있다.
이처럼 멀티 스레딩을 구현하였을 때는 미세한 실행 순서를 잘 파악해야 한다. 언제 실행되는 지가 중요하다. 이러한 비동기 처리 문제는 나중에 자바스크립트할 때 많이 발생한다. 예를 들어, 자바스크립트에서 보였다 보이지 않았다 한다면 그 프로그램은 비동기 처리를 제대로 해주지 않아서 잘 동작하지 않는 것이다. 일단 데이터를 가져오는 스레드가 동작하고 색을 바꾸는 스레드가 작업해야 하는데, 이 순서가 뒤바뀌면 색을 바꿀 데이터가 없으니 프로그램 동작이 보였다 보이지 않았다 하는 것이다.
스레드는 스레드풀을 통해 재사용할 수 있어도 소켓은 재사용할 수 없다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public void service(int port) {
notifyApplicationContextListenerOnServiceStarted();
try (ServerSocket serverSocket = new ServerSocket(port)) {
System.out.println("서버 실행 중...");
while (true) {
Socket clientSocket = serverSocket.accept();
if (stop) {
break;
}
// 직접 스레드를 생성하는 것이 아니라 스레드풀에 작업을 맡긴다.
threadPool.execute(() -> handleClient(clientSocket));
}
} catch (Exception e) {
e.printStackTrace();
}
notifyApplicationContextListenerOnServiceStopped();
threadPool.shutdown();
}
클라이언트 앱을 실행해서 다음과 같이 입력한다.
1
2
3
4
5
6
7
8
9
10
11
(master)⚡ % java -cp bin/main com.eomcs.pms.ClientApp localhost 8888
명령> /hello
안녕하세요!
명령> /board/list
[게시물 목록]
1, 1, 1, 2020-09-24, 0
1, 1, , 2020-09-25, 0
4, 4, 4, 2020-09-25, 0
명령> stop
서버를 종료하는 중입니다!
안녕!
서버 앱의 실행 결과는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
프로젝트 관리 시스템(PMS)에 오신 걸 환영합니다!
'board.json' 파일에서 총 3 개의 객체를 로딩했습니다.
'member.json' 파일에서 총 1 개의 객체를 로딩했습니다.
'project.json' 파일에서 총 1 개의 객체를 로딩했습니다.
'task.json' 파일에서 총 1 개의 객체를 로딩했습니다.
서버 실행 중...
[Thread-0] - 스레드 생성!
[Thread-0] - 스레드 대기 중...
[Thread-0] - 스레드 작업 시작!
클라이언트(127.0.0.1)가 연결되었습니다.
클라이언트(127.0.0.1)와의 연결을 끊었습니다.
[Thread-0] - 스레드 작업 종료!
[Thread-0] - 스레드풀로 되돌아 감!
[Thread-0] - 스레드 대기 중...
[Thread-0] - 스레드 꺼내서 재사용!
[Thread-0] - 스레드 작업 시작!
클라이언트(127.0.0.1)가 연결되었습니다.
클라이언트(127.0.0.1)와의 연결을 끊었습니다.
[Thread-0] - 스레드 작업 종료!
[Thread-0] - 스레드풀로 되돌아 감!
[Thread-0] - 스레드 대기 중...
[Thread-0] - 스레드 꺼내서 재사용!
[Thread-0] - 스레드 작업 시작!
클라이언트(127.0.0.1)가 연결되었습니다.
[Thread-0] - 스레드 작업 종료!
[Thread-0] - 스레드풀로 되돌아 감!
[Thread-0] - 스레드 대기 중...
프로젝트 관리 시스템(PMS)을 종료합니다!
총 3 개의 객체를 'board.json' 파일에 저장했습니다.
총 1 개의 객체를 'member.json' 파일에 저장했습니다.
총 1 개의 객체를 'project.json' 파일에 저장했습니다.
총 1 개의 객체를 'task.json' 파일에 저장했습니다.
클라이언트를 하나만 연결했기 때문에 스레드가 하나만 생성되어 다시 대기열로 되돌아가고 다시 사용되고 있다. 그러나 수업시간에 강사님 컴퓨터로 23명의 학생이 동시에 접속하였을 때는 스레드가 하나 더 생겨서 (Thread-0과 Thread-1) 23명이 요청한 작업들을 수행하였다.
즉 동접자가 n명이라고 n개의 스레드가 생기는 것이 아니다. 동접자가 만 명 정도 되면 10개 정도의 스레드가 만들어진다. 단 이 개수는 정해진 게 아니라 CPU 램 속도가 얼마나 빠른지에 따라 다르다. 실무에서는 시스템 엔지니어링 팀이 하드웨어를 관리하면서 최소와 최대 스레드 수를 조절할 수 있다. 메모리 한계가 있어서 스레드 수를 무한정 증가시킬 수 없다. 그러지 않으면 시스템이 뻗어버린다(급격하게 느려진다). 그럴 위험이 있거나 그런 일이 자주 발생한다면 시스템(하드웨어)을 확장해야 한다.
ServerApp.service()
마지막 코드에 threadPool.shutdown()를 삽입해야 한다. 만약 shutdown()호출하지 않는다면, 메인 스레드가 죽더라도 다른 스레드가 살아있을 경우 시스템 종료가 되지 않는다.스레드가 작업을 하는 중이 아니라 하더라도 스레드풀에 스레드들이 대기 상태로 살아 있기 때문에 다음과 같이 메인 스레드는 죽지만 프로그램 자체는 종료가 되지 않는다.
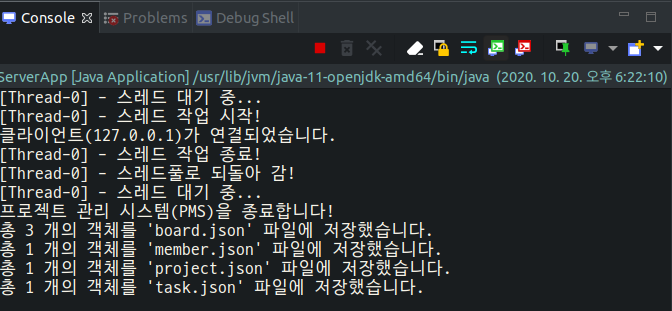
1
2
3
4
5
public void service(int port) {
//..
notifyApplicationContextListenerOnServiceStopped();
threadPool.shutdown();
}
위와 같이 threadPool.shutdown()을 호출하면
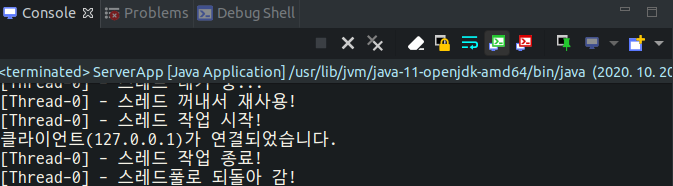
시스템이 정상적으로 종료된 것을 확인할 수 있다.
자바에서 제공하는 스레드풀 사용하기
Concurrent 프레임워크
- 동시성 프로그래밍ㅇ을 위해 자바에서 제공하는 프레임워크이다.
스레드풀이나 비동기 입출력, 간단한 태스크 프레임워크 포함
- 멀티 스레드를 사용할 것이다.
- 스레드 풀을 사용할 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
public class ServerApp {
ExecutorService threadPool = Executors.newCachedThreadPool();
//..
public void service(int port) {
notifyApplicationContextListenerOnServiceStarted();
try (ServerSocket serverSocket = new ServerSocket(port)) {
System.out.println("서버 실행 중...");
while (true) {
Socket clientSocket = serverSocke.accept();
if (stop) {
break;
}
threadPool.execute(() -> handleClient(clientSocket));
}
} catch (Exception e) {
e.printStackTrace();
}
notifyApplicationContextListenerOnServiceStopped();
threadPool.shutdown();
try {
if (!threadPool.awaitTermination(10, TimeUnit.SECONDS)) {
System.out.println("아직 종료 안 된 작업이 있다.");
System.out.println("남아 있는 작업의 강제 종료를 시도하겠다.");
threadPool.shutdownNow();
if (!threadPool.awaitTermination(5, TimeUnit.SECONDS)) {
System.out.println("스레드풀의 강제 종료를 완료하지 못했다.");
} else {
System.out.println("모든 작업을 강제 종료했다.");
}
}
} catch (Exception e) {
System.out.println("스레드풀 강제 종료 중 오류 발생!");
}
System.out.pirnltn("서버 종료!");
}
//...
}
DBMS
현재 요구사항
이때까지는 개발자가 직접 data 관리를 위해 파일을 조작하였다. 이 방식은 데이터 크기가 작을 때는 괜찮지만, 데이터가 많을 때는 사용할 수 없다. 즉 상용으로는 사용할 수 없다. 그러나 다음과 같은 문제점이 있었다.
- 임의의 위치의 값 변경
- 특정 조건에 해당하는 데이터 찾기
- 특정 조건의 data 삭제
- 대량의 데이터를 다루기 쉽게 어떤 기법으로 여러 파일로 분산 저장할 것인가?
- data와 data 간의 관계는 어덯게 관리할 것인가?
- 유효하지 않은 data 조작을 어떻게 제한할 것인가?
- 이미 삭제된 회원이 프로젝트리스트에서 팀원이 된다.
일반적인 프로그램은 괜찮지만 기업용 프로그램에서는 이런 것들이 반드시 해소되어야 한다. 그러나 이런 문제점을 모두 수용하려면 많은 코딩을 해야 하고, 많은 사람들이 중복해서 코딩해야 한다. 이걸 Data 관리 전문 소프트웨어(Data Base Management System; DBMS)가 해결을 해줄 수 있다.
DBMS
- data 관리 전문 소프트웨어(Data Base Management System; DBMS)
- ex: Oracle, My-SQL, MS-SQL, DB2, (국산: Altibase, Cubrid, Tibero)
- 유료 소프트웨어는 개인 대상은 업그레이드 비용만 내면 되지만, 회사의 경우 유지보수 비용을 해마다 내야 한다.
- 2016년은 CPU당 라이센스 비용을, 지금은 코어당 라이센스 비용을 내야 한다. 동시접속자 수에 대해서도 라이센스 비용을 내야 하고, 연 라이센스 비용도 내야 한다.
MariaDB는 오픈 소스로 무료고, Oracle은 비용이 많이 든다.
- Google과 Facebook은 직원들이 엔지니어로 구성되어 있어 문제가 발생하면 알아서 해결할 수 있다. 반면 한국기업들이나 관공서에서 MariaDB를 안 쓰고 비싼 Oracle을 사용하는 이유는 문제가 발생하면 관리자들이 책임을 져야 한다. Google이나 Facebook처럼 엔지니어로 구성된 게 아니라 디비에서 발생된 문제를 찾아내 해결할 수도 없기 때문에 Oracle을 사용한다.
종류
- Relational DBMS
- Oracle, My-SQL, MS-SQL, DB2, (국산: Altibase, Cubrid, Tibero)
- MariaDB: MySQL 창시자가 MySQL 똑같이 복사해서 만들어서 호환이가능하다
- O-RDBMS
- PostgreSQL (데이터를 객체처럼 다루기 위해 )
- 기업에서 잘 사용하지 않는다.
- NoSQL DBMS
- [key-value] 형태로 데이터를 다룬다.
- MongoDB(JSON데이터 형식): 몽고 디비
- RDBMS는 단순 데이터 저장하기에는 너무 무겁다. 이러한 단순 데이터를 저장할 때는 NoSQL을 사용한다. 그러나 RDBMS를 완전히 대체할 수는 없다.
RDBMS를 써야 할 때도 있고 다른 종류의 DBMS를 써야 할 때도 있다. 방문자의 성별, 연령대, 방문 시간과 같이 단순한 데이터를 대량으로 저장하고 싶다고 하자. 자잘한 데이터가 대량으로 발생한다. 데이터 크기 자체가 큰 게 아니라 자잘한 데이터가 어마어마하게 발생할 때 이를 빅데이터라 한다. 자잘한 대량의 데이터에서 마케팅에 필요한 정보를 추출하는 데 유용하다.
RDBMS
App과 DBMS는 별도의 프로그램이기 때문에 통신을 해야 한다. App이 요청하면 DBMS는 응답한다.
- data 저장, 조회
- data 변경, 삭제, 찾기
- client 인증 및 권한 관리
- data 간의 관계를 제어 -> 결함이 생기지 않게 제어 -> 무결성(Integrity; 온전함)
- 통신 관리: stateless / stateful
- 멀티 스레딩: 여러 어플리케이션이 붙어서 데이터를 요청한다.
- 스레드풀이 구현되어 있다.
이와 같이 수많은 기능을 DBMS가 갖추고 있다.
DBMS와 SQL
- 로컬이라 하더라도 전혀 다른 컴퓨터인 것처럼 서로 통신해야 한다.
- SQL(Structured Query Language): 명령을 작성하는 문법: 표준
- 특정 DBMS로부터 독립적으로 사용한다.
- 특정 Vendor의 DBMS에 종속되지 않는다.
- 표준 SQL을 따르기만 한다면 어떤 DBMS도 사용할 수 있다.
1
2
3
select name, email
from member
where name like '홍%'
SQL + a
Oracle DBMS가 SQL 2011버전을 사용한다고 하자. 그렇지만 SQL 2011버전의 일부는 지원하지 않을 수 있다. 또한 여기에 oracle 전용 문법이라고 oracle DBMS에서만 유효한 명령이 포함되어 있다. 즉,
- 모든 DBMS가 SQL표준을 완벽히 지원하지 못한다.
- 일부 문법은 지원하지 못할 수 있다.
- 또는 DBMS마다 지원하는 SQL버전도 다르다.
- 같은 DBMS라도 버전마다 지원하는 SQL이 다르다.
따라서 개발자는 사용할 DBMS에 맞춰 SQL을 작성해야 한다.
SQL과 개발 현실
SQL문 = 표준 SQL + DBMS 전용 문법
- “같은 Vendor의 DBMS”(같은 제품)라 하더라도 버전마다 사용할 수 있는 문법이 차이가 난다.
- DBMS가 다른 Vendor의 제품이라면 전용 문법이 다르기 때문에 동작이 안될 수 있다.
왜 표준 SQL을 사용하지 않을까?
- DBMS마다 사용 가능한 문법이 다를 수 있다.
- DBMS전용 문법은 DBMS 성능을 극한으로 이용할 수 있다.
- 표준 SQL문법만 사용하면 이런 이점을 누릴 수 없다.
- 개발자로 DBMS 상황에 맞춰 SQL을 변경해 줘야 한다.