
최근 다중 서버 환경에서 로컬 캐시를 글로벌 캐시로 변경해야 하는 상황이 있었는데, 작업을 하면서 예전에 시스템 디자인 강의 때 배운 캐싱 개념을 다시 짚어보게 되었다.
Cache
캐시 사용 이유
- Repeat: 반복적인 호출이 있는 데이터
- Immutability: 정적인(static) 데이터 (html, css, images..)
- Computation heavy: 비용이 많은 작업의 결과물
- ex) 만약 특정 지점에서 특정 목적지로 가는 최단거리를 구하는 알고리즘의 시간복잡도가 O(2^n)이라고 해보자. 이 결과를 요청할 때마다 계산을 한다면 서버의 부담이 커질 것이다. 요청할 때마다 계산을 하는 것이 아니라 한번 계산을 하고 이 결과를 캐시하여 가져올 수 있도록 만들면 server failure가 감소할 것이다.
- 실제 구글맵, 카카오맵에서도 캐시를 통해 목적지 계산 결과를 리턴하고 있다.
조회
facebook 에서 캐시를 사용해 post 를 조회한다고 해보자.
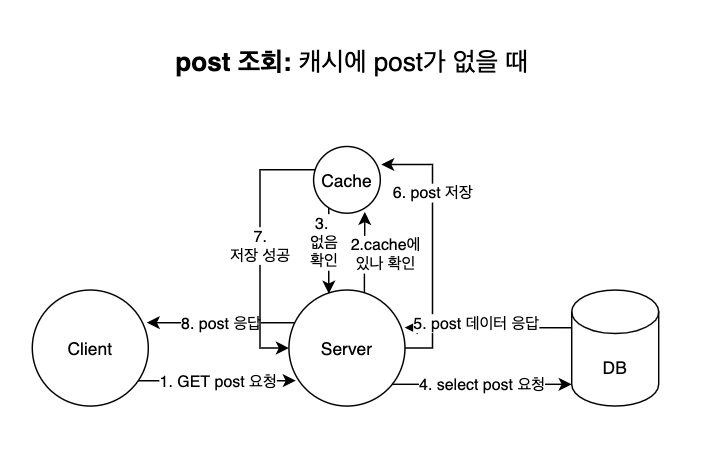
캐시에 post 데이터가 없을 때 post 조회 요청을 하면 다음과 같은 프로세스로 진행된다.
- 클라이언트가 GET /post 요청을 서버에 한다.
- 서버는 캐시에 해당 post 데이터가 있는 지 확인한다.
- 없다면, DB에 select 요청을 해 post 데이터를 가져온다.
- post를 캐시에 저장한다.
- 서버는 클라이언트에 post 정보를 응답한다.
위와 같이 캐시에 데이터가 없을 때는 지연 시간(latency)가 증가한다.
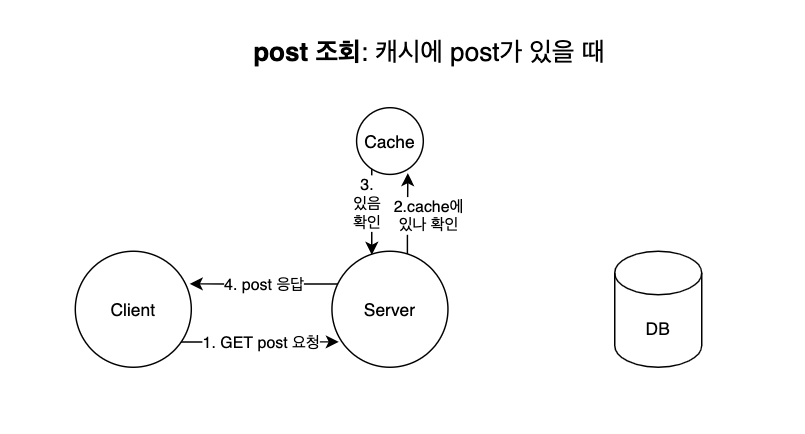 캐시 후에는 클라이언트에 빠르게 응답할 수 있다. 캐시에 post 데이터가 없을 때 post 조회 요청을 하면 다음과 같은 프로세스로 진행된다.
캐시 후에는 클라이언트에 빠르게 응답할 수 있다. 캐시에 post 데이터가 없을 때 post 조회 요청을 하면 다음과 같은 프로세스로 진행된다.
- 클라이언트가 GET /post 요청을 서버에 한다.
- 서버는 캐시에 해당 post 데이터가 있는 지 확인한다.
- 있다면, post를 가져온다.
- 서버는 클라이언트에 캐시에서 읽어온 post 정보를 응답한다.
따라서 첫번째 요청보다는 빠르게 응답할 수 있다.
수정
조회는 위와 같은 프로세스로 일어나는데, 만약 post를 edit한다면 어떻게 될까? 이렇게 데이터 변경 시 캐시 메모리와 디비의 데이터 저장 시점에 관한 정책을 캐시 쓰기 정책(Cache Write Policy)라고 한다. 두 가지 방법을 사용할 수 있는데, Write Through와 Write Back이 그것이다.
Write through
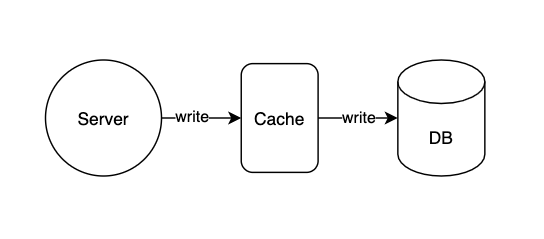
캐시와 DB 둘다에 업데이트를 해버리는 방식이다.
- 장점: 캐시와 디비에 업데이트를 함께 해, 데이터의 일관성(consistency)을 유지할 수 있어서 안정적이다.
- 단점: DB에 업데이트를 치는 비용이 있기 때문에 지연 시간(latency)이 증가한다.
- 적절한 상황: 데이터의 일관성이 중요할 때 사용한다.
- 프로세스
- 클라이언트에서 post 수정 요청을 보낸다.
- 서버는 우선 캐시를 업데이트한다.
- 그리고 DB를 업데이트한다.
- 클라이언트에 응답한다.
write back cache
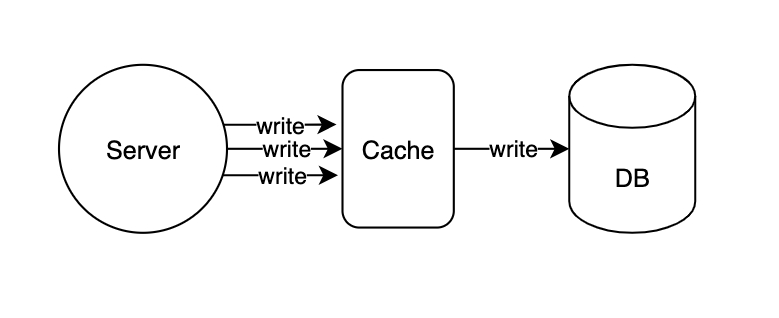
서버는 캐시에 먼저 데이터를 쓰고 클라이언트에 응답하고, 약간의 지연 후에 데이터를 다시 데이터베이스에 쓴다.
- 장점: 데이터베이스에 대한 쓰기 비용을 줄일 수 있다. (latency가 감소한다.)
- 단점
- 데이터의 일관성(consistency)이 write through 에 비해 떨어진다.
- 동시에 여러 클라이언트가 요청을 한다면 업데이트 이전 데이터를 가져올 수도 있다. (이는 다중 서버 환경일 시 발생할 수 있는 문제이다.)
- 데이터의 일관성(consistency)이 write through 에 비해 떨어진다.
- 적절한 상황
- 데이터의 일관성이 중요할 때 사용한다.
- 쓰기가 많을 때 사용한다.
- 프로세스
- 클라이언트에서 post 수정 요청을 보낸다.
- 서버는 우선 캐시를 업데이트한다.
- 캐시 변경을 기록한다.
- 클라이언트에 응답한다.
- 서버는 asynchronous하게 변경 기록을 보고 그에 맞게 n초마다 DB를 업데이트한다.
적절한 캐시 쓰기 정책?
그렇다면 write through 와 write back 중 어떤 캐시 쓰기 정책을 사용해야 할까?
⇒ 서비스의 특성에 따라 다르다!
- facebook feed: 업데이트가 바로바로 확인이 되어야 한다. ⇒ write through
- blog: 업데이트가 바로 반영되지 않아도 된다. ⇒ write back
캐시 사용처
- 프론트: 인증, html, css, javascript, images..
- 백엔드: 그냥 많이 쓰임
- 하드웨어: CPU cache L1/L2/L3
다중 서버 환경에서의 캐시
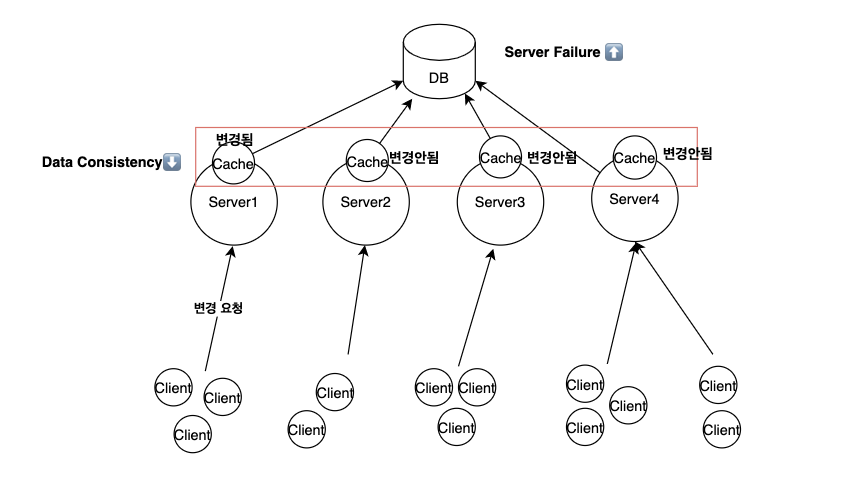
- Youtube comment system을 생각해보자. 클라이언트가 “댓글 수정” 요청을 보내고, 이 요청이 서버1에 닿는다면, 서버1은 해당 요청을 수행하여 캐시와 DB를 업데이트할 것이다.
- 그러나 이때 업데이트한 캐시는 서버1이 사용하고 있는 캐시이기 때문에 다른 서버가 사용하는 캐시에는 여전히 변경이 되지 않은 상태이다.
- 따라서 다른 유저가 요청을 했을 때 변경 전의 데이터를 볼 수 있다는 것이다. 즉, Data Consistency가 떨어진다.
- 또한 최신 정보를 가져오기 위해 캐시가 아니라 DB를 계속 조회해야 한다면 Server Failure가 높아질 것이다.
- 그렇다면 캐시를 사용할 때 어떻게 하면 DB 조회를 최소화하고, 데이터의 일관성을 유지할 수 있을까?
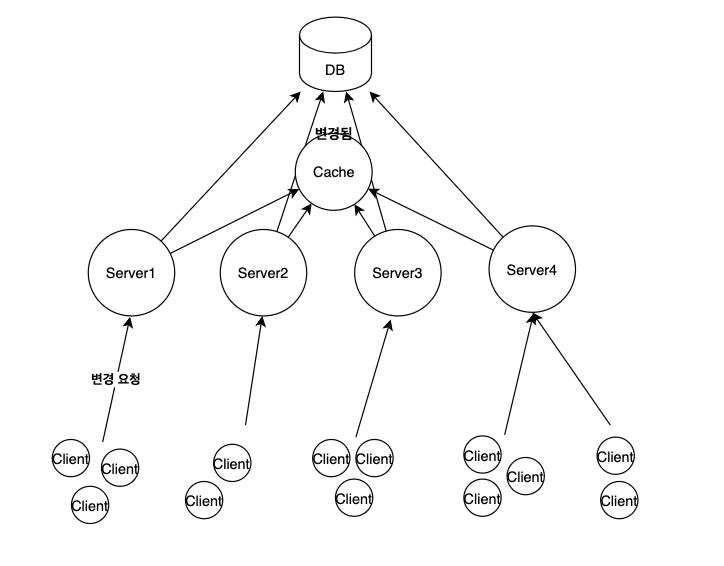
- 위 그림과 같이 여러 대의 서버가 하나의 캐시 저장소를 공유하면 된다. 그럼 다른 서버들도 변경이 반영된 최신의 데이터를 가져올 수 있다.
Cache Eviction
- 캐시 공간이 필요할 때 어떤 데이터를 지우는 것을 Eviction이라고 한다.
- LRU와 LFU 알고리즘이 있다.
LRU (Least Recently Used)
캐시의 크기가 한계에 이르면, 사용된 지 오래된 순으로 제거한다.
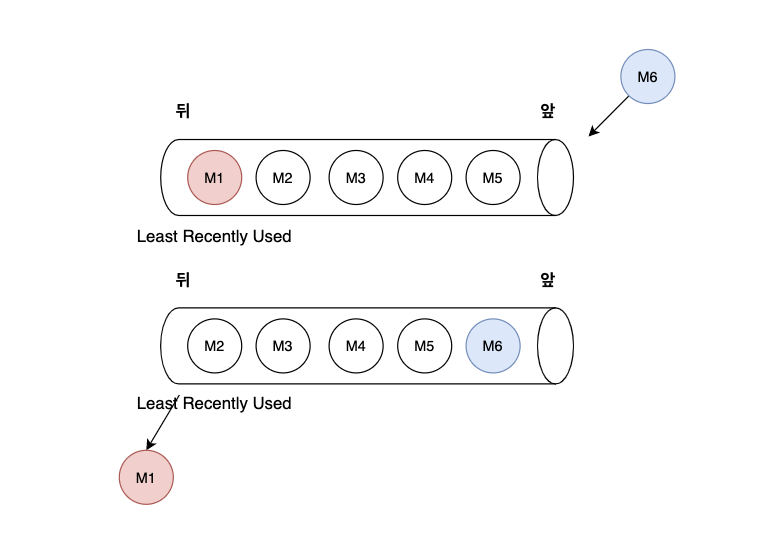
캐시의 크기가 5라 가정할 때, LRU 캐시 만료 정책을 사용하는 캐시는 다음과 같은 순서로 진행된다.
- M1, M2, M3, M4, M5 순으로 데이터를 넣는다.
- M1이 가장 뒤에 있고, M5가 앞에 있다.
- 새로운 M6 객체를 삽입하려고 시도할 때, 캐시의 크기가 한계에 이르렀기 때문에 Eviction을 수행한다.
- 가장 뒤에 있는(사용된 지 가장 오래된) M1 객체를 제거한다.
- M6객체는 앞으로 들어온다. 또 다른 M7 객체가 들어온다면 M2를 제거하고 M6 앞으로 들어올 것이다.
LFU (Least Frequently Used)
캐시의 크기가 한계에 이르면, 사용된 빈도가 낮은 순으로 제거된다.
LFU는 내부적으로 사용 빈도수를 측정하는 Frequency Table을 갖고 있다.
다음과 같이 Frequency Table이 있고, 현재 캐시가 꽉 차 있다고 가정하자.
1
2
3
4
5
6
FrequencyTable = {
1: [ M1, M2 ],
2: [ M3, M4 ],
3: [ M5 ],
4: [ M6 ]
};
M2를 사용했다면 다음과 같이 FrequencyTable이 변한다.
1
2
3
4
5
6
FrequencyTable = {
1: [ M1 ],
2: [ M3, M4, M2 ],
3: [ M5 ],
4: [ M6 ]
};
새로운 M7 객체가 들어온다고 할 때, 이미 캐시는 꽉 차 있기 때문에 Eviction을 진행해야 한다. 현재 키가 1인 M1이 가장 사용 빈도수가 낮으므로, M1이 제거된다.
1
2
3
4
5
FrequencyTable = {
2: [ M3, M4, M2 ],
3: [ M5 ],
4: [ M6 ]
};
다음에 또 다른 객체가 들어온다면, 현재 가장 낮은 빈도수인 (key가 2인 배열의 요소 중 하나) 객체가 제거될 것이다.