
Section 6. 스프링 DB 접근 기술
실무에서는 MySql이나 Oracle DB가 많이 쓰이는데, 특히 MySql 계열 DB를 많이 사용된다.
1강. H2 데이터베이스 설치
개발이나 테스트 용도(교육용)로 가볍고 편리한 DB, 웹 화면 제공
H2 공식 사이트에서 다운로드 및 설치
h2 데이터베이스 버전은 스프링 부트 버전에 맞춘다.
권한 주기:
chmod 755 h2.sh실행:
/h2.sh데이터베이스 파일 생성 방법
jdbc:h2:~/test(최초 한번)

~/test.mv.db파일 생성 확인- 이후부터는 ` jdbc:h2:tcp://localhost/~/test`
JDBC URL에 있는 값
jdbc:h2: ~/test는 파일 경로이다. 이렇게 파일로 접근하게 되면 애플리케이션과 웹 콘솔이 충돌할 수 있기 때문에 값을jdbc:h2:tcp://localhost/~/test로 바꿔준다. 파일을 직접 접근하는 것이 아니라, 소켓을 통해 접근하게 만든다. 이제 여러 곳에서 에러 없이 접근할 수 있다.
만약 문제가 있다면
rm test.vs.db명령어로 파일 자체를 지우고, 서버를 닫고, 다시 처음부터 시도한다.
테이블 생성하기
테이블 관리를 위해 프로젝트 루트에 sql/ddl.sql 파일을 생성
1
2
3
4
5
6
7
drop table if exists member CASCADE;
create table member
(
id bigint generated by default as identity,
name varchar(255),
primary key (id)
)
- H2 데이터베이스에 접근해서
member테이블 생성 bigint: long 타입generated by default as identity: 값을 셋팅하지 않고 insert 했을 때 값을 자동으로 채워준다. 즉 PK 값에 대한 생성을 DB가 알아서 하도록 넘긴 것이다.
H2 데이터베이스가 정상 생성되지 않을 때
- H2 데이터베이스를 종료하고 다시 시작한다.
- 웹 브라우저가 자동 실행되면 주소창에 localhost가 아니라 임의의 숫자(ex: 100.1.2.3)가 나온다.
- 앞 부분만 임의의 숫자(ex: 100.1.2.3) =>
localhost로 변경하고 Enter를 입력한다. 나머지 부분은 절대 변경하면 안 된다. (특히 뒤의 세션 부분이 변경되면 안 된다.) - 데이터베이스 파일을 생성하면(
jdbc:h2:~/test), 데이터베이스가 정상 생성된다.
2강. 순수 Jdbc
환경 설정
build.gradle 파일에 jdbc, h2 데이터베이스 관련 라이브러리 추가
1
2
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
runtimeOnly 'com.h2database:h2'
spring-boot-starter-jdbc: 자바는 기본적으로 DB와 붙으려면 JDBC 드라이버가 꼭 있어야 한다.com.h2database:h2: DB에 붙으려면 DB가 제공하는 클라이언트가 필요하다.
작성 후 intelliJ에서는 buid.gradle에서 코끼리 아이콘을 클릭하면 라이브러리가 다운받아진다.
스프링 부트 데이터베이스 연결 설정 추가
resources/application.properties
DB 접속 정보를 적어야 한다.
1
2
3
spring.datasource.url=jdbc:h2:tcp://localhost/~/test
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.username=sa
주의: 스프링부트 2.4부터는
spring.datasource.username=sa를 꼭 추가해주어야 한다. 그렇지 않으면wrong user name or password오류가 발생한다. 또한 마지막에 공백이 들어가면 같은 오류가 발생한다. 공백은 모두 제거해야 한다.
참고: 인텔리J 커뮤니티 버전의 경우
application.properties파일의 왼쪽이 회색으로 나온다. 엔터프라이즈 버전에서 제공하는 스프링의 소스 코드를 연결해주는 편의 기능이 빠진 것인데, 실제 동작에는 아무런 문제가 없다.
Jdbc 리포지토리 구현
회원을 저장한다는 역할은 MemberRepository가 하지만, 구현은 메모리에 저장할 것인지, DB와 연동해서 저장할 것인지에 따라 다르다. 한편 이렇게 JDBC API로 직접 코딩하는 것은 20년 전 이야기다.
Jdbc 회원 리포지토리
1
2
3
4
5
6
7
8
9
10
public class JdbcMemberRepository implements MemberRepository {
private final DataSource dataSource;
public JdbcMemberRepository(DataSource dataSource) {
this.dataSource = dataSource;
}
//..
}
DB에 붙으려면 DataSource라는 것이 필요하다. 그리고 이것을 스프링으로부터 주입받는다. 그리고 이 dataSource로 부터 getConnection을 해서 열린 소켓을 얻을 수 있다. 여기에 sql문을 보내서 DB에 전달해주면 된다.
insert into member(name) values(?): 파라미터 바인딩을 위해 물음표를 사용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
package hello.hellospring.repository;
public class JdbcMemberRepository implements MemberRepository {
private final DataSource dataSource;
public JdbcMemberRepository(DataSource dataSource) {
this.dataSource = dataSource;
}
@Override
public Member save(Member member) {
// 여기서는 sql 문자열을 로컬 변수로 선언했지만
// 상수로 해주는 것이 좋다.
String sql = "insert into member(name) values(?)";
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
conn = getConnection();
// insert를 할 때 자동 생성되는 값을 가져오기 위함
pstmt = conn.prepareStatement(sql,
Statement.RETURN_GENERATED_KEYS);
pstmt.setString(1, member.getName());
// DB에 실제 쿼리가 날아간다.
pstmt.executeUpdate();
// insert 시 자동 생성된 값을 가져옴
rs = pstmt.getGeneratedKeys();
// 값이 있으면 값을 꺼낸다.
if (rs.next()) {
member.setId(rs.getLong(1));
} else {
throw new SQLException("id 조회 실패");
}
return member;
} catch (Exception e) {
throw new IllegalStateException(e);
// 자원 release
// DB 커넥션 같은 경우 외부 네트워크와 연결된 것이기 때문에 끝나면 바로 자원을 반환해야 한다.
// 그렇지 않으면 DB 커넥션이 쌓이다가 큰 장애가 발생할 수 있다!!!!
} finally {
close(conn, pstmt, rs);
}
}
@Override
public Optional<Member> findById(Long id) {
String sql = "select * from member where id = ?";
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
conn = getConnection();
pstmt = conn.prepareStatement(sql);
pstmt.setLong(1, id);
// 조회는 executeUpdate가 아닌 executeQuery
rs = pstmt.executeQuery();
// 값이 있으면 객체 생성
if (rs.next()) {
Member member = new Member();
member.setId(rs.getLong("id"));
member.setName(rs.getString("name"));
return Optional.of(member);
} else {
return Optional.empty();
}
} catch (Exception e) {
throw new IllegalStateException(e);
} finally {
close(conn, pstmt, rs);
}
}
@Override
public List<Member> findAll() {
String sql = "select * from member";
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
conn = getConnection();
pstmt = conn.prepareStatement(sql);
rs = pstmt.executeQuery();
List<Member> members = new ArrayList<>();
while (rs.next()) {
Member member = new Member();
member.setId(rs.getLong("id"));
member.setName(rs.getString("name"));
members.add(member);
}
return members;
} catch (Exception e) {
throw new IllegalStateException(e);
} finally {
close(conn, pstmt, rs);
}
}
@Override
public Optional<Member> findByName(String name) {
String sql = "select * from member where name = ?";
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
conn = getConnection();
pstmt = conn.prepareStatement(sql);
pstmt.setString(1, name);
rs = pstmt.executeQuery();
if (rs.next()) {
Member member = new Member();
member.setId(rs.getLong("id"));
member.setName(rs.getString("name"));
return Optional.of(member);
}
return Optional.empty();
} catch (Exception e) {
throw new IllegalStateException(e);
} finally {
close(conn, pstmt, rs);
}
}
// dataSource.getConnection()을 하면 계속해서 새로운 커넥션이 주어진다.
// 스프링 프레임워크를 통해 커넥션을 쓸 때는
// dataSourceUtils을 통해서 커넥션을 획득해야 한다.
// 그래야 이전에 DB 트랜잭션이 걸릴 수 있는데 그러면 DB 커넥션을 똑같은 걸로 유지시켜줘야 한다. 이걸 유지시켜줌.
private Connection getConnection() {
return DataSourceUtils.getConnection(dataSource);
}
private void close(Connection conn, PreparedStatement pstmt, ResultSet rs) {
try {
if (rs != null) {
rs.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
try {
if (pstmt != null) {
pstmt.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
try {
if (conn != null) {
close(conn);
}
} catch (SQLException e) {
e.printStackTrace();
}
}
// 닫을 때도 dataSourceUtils을 통해서 닫는다.
private void close(Connection conn) throws SQLException {
DataSourceUtils.releaseConnection(conn, dataSource);
}
}
MemberRepository 인터페이스를 구현체를 하나 더 만들어서 확장하였다.
스프링 설정 변경
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
package hello.hellospring;
@Configuration
public class SpringConfig {
private DataSource dataSource;
@Autowired
public SpringConfig(DataSource dataSource) {
this.dataSource = dataSource;
}
@Bean
public MemberService memberService() {
return new MemberService(memberRepository());
}
@Bean
public MemberRepository memberRepository() {
//return new MemoryMemberRepository();
return new JdbcMemberRepository();
}
}
객체지향적 설계가 좋은 이유? 이걸 다형성이라고 부른다. 인터페이스를 두고 구현체를 바꿔끼기를 할 수 있다. 스프링에서는 이것을 아주 쉽게 할 수 있도록 스프링 컨테이너를 통해서 지원한다. DI를 통해. 스프링 없이 DB를 변경하려면? MemberService의 생성자와 필드를 MemoryMemberRepository에서 JdbcMemberRepository로 바꿔줘야 할 것이다. 즉 코드의 수정이 있어야 한다. 반면 스프링의 DI를 사용하면 기존 코드는 전혀 손대지 않고, 설정 파일 변경만으로 구현 클래스를 변경할 수 있다. 이때 설정은 객체 Assemble(조립)이라고도 한다. 즉 조립하는 코드만 변경하면 구현체를 교체할 수 있다.
DataSource는 데이터베이스 커넥션을 획득할 때 사용하는 객체다. 스프링 부트는 데이터베이스 커넥션 정보를 바탕으로 DataSource를 생성하고 스프링 빈으로 만들어둔다. 그래서 DI를 받을 수 있다.
- 개방-폐쇄 원칙(OCP, Open-Closed Principle)
- 확장에는 열려있고, 수정, 변경에는 닫혀있다.
- 스프링의 DI(Dependencies Injection)을 사용하면 기존 코드는 전혀 손대지 않고, 설정만으로 구현 클래스를 변경할 수 있다.
- 데이터를 DB에 저장하므로 스프링 서버를 다시 실행해도 데이터가 안전하게 저장된다.
객체지향의 진짜 매력은 기존 코드를 변경 없이 인터페이스의 구현체를 교체할 수 있는 것
3강. 스프링 통합 테스트
스프링 컨테이너와 DB까지 연결한 통합 테스트를 진행한다.
순수한 자바 코드로 JdbcMemberRepository 테스트 코드를 작성할 수 없다. DB 커넥션도 스프링 부트가 들고 있기 때문이다. 이제부터는 테스트를 스프링과 엮어서 할 것이다.
스프링 컨테이너에게 MemberService, MemberRepository 내놓으라고 해야 한다. Test는 제일 끝단에 있기 때문에 가장 편한 방법을 사용하면 된다. Test를 다른 곳에서 갖다 쓸 것이 아니라 Test에서 Injection받아서 사용할 것이기 때문이다.
1
2
3
4
5
6
7
@SpringBootTest
class MemberServiceIntegrationTest {
@Autowired MemberService memberService;
@Autowired MemberRepository memberRepository;
//..
}
다음 테스트에 영향을 주지 않도록 저장공간을 비워주는 afterEach() 메서드도 삭제한다. 필요가 없기 때문이다.
보통 Test 전용 DB를 따로 구축을 하거나 로컬 PC에 있는 DB로 테스트를 한다.
이전 Test에서는 Spring이 뜨지 않았는데 이번에는 뜬다. Test가 끝나면 Spring이 내려간다.
Test는 반복할 수 있어야 한다. 하지만 지금은 다시 Test를 돌리면 같은 이름으로 회원을 저장할 수 없기 때문에 오류를 던진다. DB는 기본적으로 Transaction이라는 개념이 있다. insert, update, delete를 했다고 바로 DB에 반영이 되는 것이 아니라, commit을 해야 비로소 DB에 반영이 된다. auto commit(자동으로 커밋이 됨)을 하냐, 하지 않느냐의 차이지. 테스트가 끝나고 바로 rollback해버리면 DB에 반영이 안 된다.
@Transactional이라는 애노테이션을 테스트 케이스에 달면, 테스트를 실행할 때 트랜잭션을 먼저 실행하고, DB에 insert 쿼리 등등을 실행한 뒤에 테스트가 끝나면 rollback을 해준다. 그러면 DB에 넣었던 데이터가 반영이 안된다.
1
2
3
@SpringBootTest
@Transactional
class MemberServiceIntegrationTest {
@SpringBootTest: 스프링 컨테이너와 테스트를 함께 실행한다.@Transactional: 테스트 케이스에 이 애노테이션이 있으면, 테스트 시작 전에 트랜잭션을 시작하고, 테스트 완료 후에 항상 롤백한다. 이렇게 하면 DB에 데이터가 남지 않으므로 다음 테스트에 영향을 주지 않는다. 단Service에@Transactional애노테이션을 붙이면 항상 롤백하지 않는다. (다르게 동작한다.)
순수하게 자바 코드로 하면서 최소한의 단위로 테스트하는 것을 단위 테스트라고 한다. 스프링 컨테이너와 DB까지 연동하는 것을 통합 테스트라고 한다. 가급적이면 스프링 없이 순수한 자바 코드로 단위로 쪼개서 테스트 하는 것이 더 좋은 방법이다. 스프링 컨테이너까지 올려서 테스트를 하는 경우는 테스트 설계가 잘못되었을 확률이 높다.
4강. 스프링 JdbcTemplate
순수 Jdbc로 개발하기 너무 어려우니까 스프링이 중복을 제거해서 Jdbc Template 이라는 기술을 제공한다. 이걸로 애플리케이션에서 데이터베이스로 sql문을 편리하게 날릴 수 있다.
- 순수 Jdbc와 동일한 환경 설정을 하면 된다.
- 스프링 JdbcTemplate과 MyBatis 같은 라이브러리는 JDBC API에서 본 반복 코드를 대부분 제거해준다. 하지만 SQL은 직접 작성해야 한다.
스프링 JdbcTemplate 회원 리포지토리
JdbcTemplate자체를 주입받을 수는 없다. 대신DataSource를 주입받아new JdbcTemplate(dataSource)로 생성한다.- 생성자가 하나만 있으면
@Autowired를 생략할 수 있다. - jdbcTemplate 라이브러리가 기존 JDBC에서 중복 코드를 줄여주었다. Template 이라고 이름 붙인 이유는 디자인 패턴 중
Template Method Pattern을 통해 만들었기 때문이다. save(Member member):JdbcTemplate객체를 넘겨서 만드는SimpleJdbcInsert객체는 재밌는 기능이 있다. 테이블명과 generated 되어야 하는 PK 컬럼명을 넘겨주면 쿼리를 짤 필요가 없다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
package hello.hellospring.repository;
public class JdbcTemplateMemberRepository implements MemberRepository {
private final JdbcTemplate jdbcTemplate;
public JdbcTemplateMemberRepository(DataSource dataSource) {
jdbcTemplate = new JdbcTemplate(dataSource);
}
@Override
public Member save(Member member) {
SimpleJdbcInsert jdbcInsert = new SimpleJdbcInsert(jdbcTemplate);
jdbcInsert.withTableName("member").usingGeneratedKeyColumns("id");
Map<String, Object> parameters = new HashMap<>();
parameters.put("name", member.getName());
Number key = jdbcInsert.executeAndReturnKey(new MapSqlParameterSource(parameters));
member.setId(key.longValue());
return member;
}
@Override
public Optional<Member> findById(Long id) {
List<Member> result = jdbcTemplate.query("select * from where id = ?", memberRowMapper(), id);
return result.stream().findAny();
}
@Override
public List<Member> findAll() {
return jdbcTemplate.query("select * from member", memberRowMapper());
}
@Override
public Optional<Member> findByName(String name) {
List<Member> result = jdbcTemplate.query("select * from member where name = ?", memberRowMapper(), name);
return result.stream().findAny();
}
// 객체 생성에 대한 일은 여기서 한다.
private RowMapper<Member> memberRowMapper() {
return (rs, rowNum) -> {
Member member = new Member();
member.setId(rs.getLong("id"));
member.setName(rs.getString("name"));
return member;
};
}
}
JdbcTemplate을 사용하도록 스프링 설정 변경
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
package hello.hellospring;
@Configuration
public class SpringConfig {
private DataSource dataSource;
@Autowired
public SpringConfig(DataSource dataSource) {
this.dataSource = dataSource;
}
@Bean
public MemberService memberService() {
return new MemberService(memberRepository());
}
@Bean
public MemberRepository memberRepository() {
//return new MemoryMemberRepository();
//return new JdbcMemberRepository(dataSource);
return new JdbcTemplateMemberRepository(dataSource);
}
}
실무에서 프로덕션 코드를 짜는 시간보다 테스트 코드를 작성하는 시간이 더 길다. 거의 60~70퍼센트 정도 된다. 작은 버그 하나가 수억, 수십억의 피해로 돌아오기 때문이다.
5강. JPA
- JPA는 기존의 반복 코드는 물론이고, 기본적인 SQL도 JPA가 직접 만들어서 실행해준다. JdbcTemplate 을 사용하면서 중복 코드는 줄었지만 여전히 SQL문은 개발자가 직접 작성해야 한다. 그러나 JPA 기술을 사용하면 SQL 쿼리도 JPA가 자동으로 처리해준다. 마치 우리가 MemoryMemberRepository에서 메모리에 객체를 넣듯이, 객체를 JPA에 집어넣으면 JPA가 중간에서 DB에 SQL을 날리고 데이터를 DB에서 가져오는 것을 처리해준다.
- JPA를 사용하면, SQL과 데이터 중심의 설계에서 객체 중심의 설계로 패러다임을 전환할 수 있다.
- JPA를 사용하면 개발 생산성을 크게 높일 수 있다.
- JPA(Java Persistance API)와 비교되는 것이 MyBatis 프레임워크이다. 국내에서는 JPA와 MyBatis의 인지도가 비슷하지만, 전 세계에서 보면 JPA가 MyBatis와 비교도 안 되게 많이 사용된다.
- JPA도 스프링만큼 성숙한 기술이고(나온 시기가 비슷하다), 학습해야 할 분량도 방대하다. 스프링도 JPA를 많이 지원한다. 특히 스프링 프레임워크에서 제공하는 관계형 데이터베이스 관련 예제들은 대개 JPA를 사용한다.
build.gradle 파일에 JPA, h2 데이터베이스 관련 라이브러리 추가
1
2
3
4
5
6
7
8
9
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-thymeleaf'
implementation 'org.springframework.boot:spring-boot-starter-web'
//implementation 'org.springframework.boot:spring-boot-starter-jdbc'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
runtimeOnly 'com.h2database:h2'
testImplementation('org.springframework.boot:spring-boot-starter-test') {
exclude group: 'org.junit.vintage', module: 'junit-vintage-engine'
}
spring-boot-starter-data-jpa는 내부에 jdbc 관련 라이브러리를 포함한다. 따라서 jdbc는 제거해도 된다.
JPA는 인터페이스(표준)이다. 이 JPA의 구현체로 Hibernate, Eclipse 등 여러 개의 벤더가 있는데, 그 중 거의 Hibernate를 많이 사용한다. spring-boot-starter-data-jpa를 작성하면 hibernate가 자동으로 의존 라이브러리에 추가된다.
스프링 부트에 JPA 설정 추가
resouces/application.properties
1
2
3
4
5
spring.datasource.url=jdbc:h2:tcp://localhost/~/test
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.username=sa
spring.jpa.show-sql=true
spring.jpa.hibernate.ddl-auto=none
스프링부트 2.4부터는
spring-datasource.username=sa를 꼭 추가해줘야 한다. 그렇지 않으면 오류가 발생한다.
show-sql: JPA가 생성하는 SQL을 출력한다.ddl-auto: JPA는 테이블을 자동으로 생성하는 기능을 제공한다. 그러나 우리는 만들어진 테이블을 사용할 것이기 때문에none를 사용하여 해당 기능을 끈다.create을 사용하면 엔티티 정보를 바탕으로 테이블도 직접 생성해준다.
JPA 엔티티 매핑
JPA는 객체와 ORM(Object Relational Mapping; 객체-관계 매핑) 기술이다. ORM이란 객체와 관계형 데이터베이스의 데이터를 자동으로 매핑(연결)해주는 것을 말한다. 객체 모델과 관계형 모델 간에 불일치가 존재하는데, ORM을 통해 객체 간의 관계를 바탕으로 SQL을 자동으로 생성하여 불일치를 해결한다. 이 매핑은 Annotation으로 만들어준다.
@Entity: 객체에 이 애노테이션을 붙이면 JPA가 관리하는 Entity가 된다.@Id: PK를 매핑@GeneratedValue(strategy=GenerationType.IDENTITY): DB에서 생성되는 값 (Identity: DB가 알아서 생성해주는 것)@Column(name="username"): 객체 필드명(name)과 컬럼명(username)이 다르다면 이 애노테이션으로 매핑한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
package hello.hellospring.domain;
@Entity
public class Member {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
JPA 회원 리포지토리
- JPA를 쓰려면 EntityManager를 주입받아야 한다.
EntityManager: JPA는 EntityManager로 모든 것이 동작한다.spring-boot-starer-data-jpa라이브러리를 다운받으면 스프링부트가 EntityManager를 자동으로 만들어준다. Entity Manager는 스프링이properties정보와 데이터베이스 커넥션 정보를 기반으로 현재 데이터베이스랑 연결을 해놓은 것이다. 그럼 이렇게 만들어진 EntityManager를 주입받으면 된다.- EntityManager는 dataSource 객체 등을 내부적으로 가지고 있다. 따라서 DB와 통신하는 것을 다 처리한다.
persist(): 영속하다. 영구 저장하다. JPA 내부적으로 insert 해주고 Generated된 PK를setId()를 호출하여 셋팅하는 일까지 해준다.find(): PK로 조회하는 것을 이 메서드를 사용하면 된다.createQuery("select m from m", Member.class): PK로 조회하는 것이 아니라면 JPQL이라는 객체지향 쿼리를 써야 한다. SQL은 테이블을 대상으로 쿼리를 날리지만, JPQL은 Entity를 대상으로 쿼리를 날린다는 게 차이점이다. 이때,select * from Member m이 아니라select m from Member m으로 객체 자체를 select한다.- 한편 스프링 데이터 JPA를 사용하면 findAll, findByName를 작성할 때 createQuery를 사용하지 않아도 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
package hello.hellospring.repository;
public class JpaMemberRepository implements MemberRepository {
private final EntityManager em;
public JpaMemberRepository(EntityManager em) {
this.em = em;
}
@Override
public Member save(Member member) {
// persist: 영속하다. 영구저장하다.
em.persist(member);
return member;
}
@Override
public Optional<Member> findById(Long id) {
Member member = em.find(Member.class, id);
return Optional.ofNullable(member);
}
@Override
public List<Member> findAll() {
return em.createQuery("select m from Member m", Member.class)
.getResultList();
}
@Override
public Optional<Member> findByName(String name) {
List<Member> result = em.createQuery("select m from Member m where m.name = :name", Member.class)
.setParameter("name", name)
.getResultList();
return result.stream().findAny();
}
}
서비스 계층에 트랜잭션 추가
1
2
@Transactional
public class MemberService {
org.springframework.transaction.annotation.Transactional을 사용한다.- 스프링은 해당 클래스의 메서드를 실행할 때 트랜잭션을 시작하고, 메서드가 정상 종료되면 트랜잭션을 커밋한다. 만약 런타임 예외가 발생하면 롤백한다.
- JPA를 통한 모든 데이터 변경은 트랜잭션 안에서 실행해야 한다.
JPA를 사용하도록 스프링 설정 변경
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
package hello.hellospring;
@Configuration
public class SpringConfig {
private final EntityManager em;
@Autowired
public SpringConfig(EntityManager em) {
this.em = em;
}
@Bean
public MemberService memberService() {
return new MemberService(memberRepository());
}
@Bean
public MemberRepository memberRepository() {
//return new MemoryMemberRepository();
//return new JdbcMemberRepository(dataSource);
//return new JdbcTemplateMemberRepository(dataSource);
return new JpaMemberRepository(em);
}
}
6강. 스프링 데이터 JPA
스프링 부트와 JPA만 사용해도 개발 생산성이 정말 많이 증가하고, 개발해야 할 코드도 확연히 줄어든다. 여기에 스프링 데이터 JPA를 사용하면, 기존의 한계를 넘어 마치 마법처럼, 리포지토리에 구현 클래스 없이 인터페이스만으로 개발을 완료할 수 있다. 그리고 반복 개발해온 CRUD 기능도 스프링 데이터 JPA가 모두 제공한다.
스프링 부트와 JPA라는 기반 위에, 스프링 데이터 JPA라는 환상적인 프레임워크를 더하면 개발이 정말 즐거워진다. 지금까지 조금이라도 단순하고 반복이라 생각했던 개발 코드들이 확연하게 줄어든다. 따라서 개발자는 핵심 비즈니스 로직을 개발하는 데 집중할 수 있다.
실무에서 관계형 데이터베이스를 사용한다면 스프링 데이터 JPA는 선택이 아니라 필수이다.
한편 스프링 데이터 JPA는 JPA를 편리하게 사용하도록 도와주는 기술이다. 따라서 JPA를 먼저 학습한 후에 스프링 데이터 JPA를 학습해야 한다.
- 앞의 JPA 설정을 그대로 사용한다.
스프링 데이터 JPA 회원 리포지토리
- interface가 interface를 받을 때는 implements가 아니라 extends 를 사용한다.
1
2
3
4
5
6
7
8
9
package hello.hellospring.repository;
public interface SpringDataJpaMemberRepository extends JpaRepository<Member/*Entity*/, Long/*PK:id*/>, MemberRepository {
// JPQL select m from Member m where m.name = ?
@Override
Optional<Member> findByName(String name);
}
스프링 데이터 JPA 회원 리포지토리를 사용하도록 스프링 설정 변경
memberRepository를 주입받게 만들면 스프링 데이터 JPA가 만들어놓은 구현체가 등록이 된다. 우리가 만든 것은 SpringDataJpaMemberRepository 인터페이스이다. 인터페이스를 생성하고 이 인터페이스가 JpaRepository를 상속하게 만들면 스프링 데이터 JPA가 인터페이스에 대한 구현체를 만들어주고, 스프링 빈에 등록을 한다. 그래서 우리는 Injection을 받을 수 있다. 주입을 받아서
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
package hello.hellospring;
@Configuration
public class SpringConfig {
private final MemberRepository memberRepository;
@Autowired // 생략가능
public SpringConfig(MemberRepository memberRepository) {
this.memberRepository = memberRepository;
}
@Bean
public MemberService memberService() {
return new MemberService(memberRepository);
}
}
스프링 데이터 JPA가 SpringDataJpaMemberRepository를 스프링 빈으로 자동 등록해준다.
스프링 데이터 JPA 제공 클래스
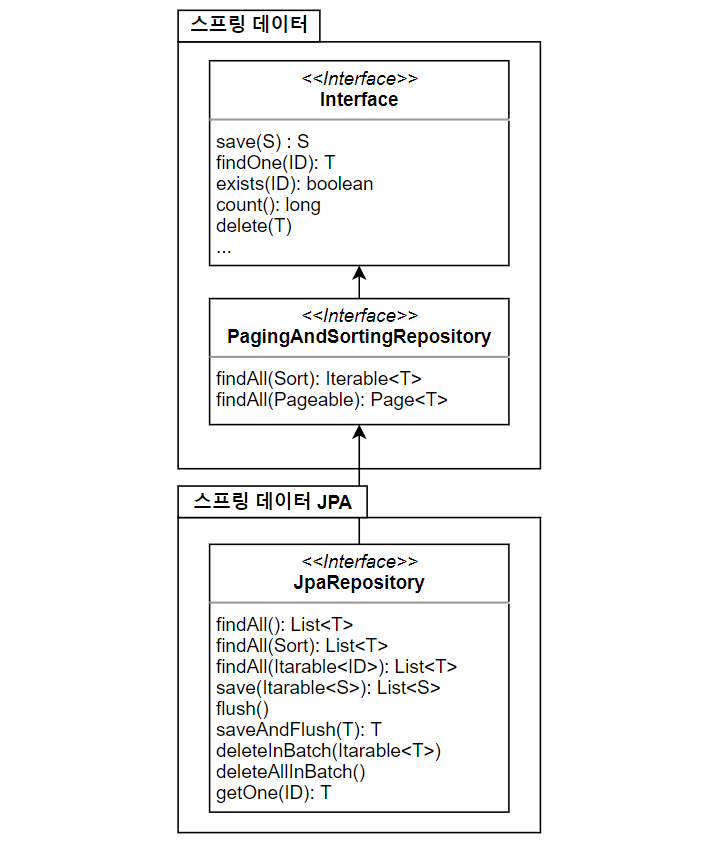
스프링 데이터 JPA 제공 기능
인터페이스를 통한 기본적인 CRUD
findByName(),findByEmail()처럼 메서드 이름만으로 조회 기능 제공JpaRepository에 있는 메서드는 공통적인 메서드이다.
findByName(),findByEmail()의 경우 비즈니즈가 다르기 때문에 공통화할 수 없을 것이다. 그래서 공통 클래스로 제공할 수 없다. 인터페이스에findByName(String name);를 작성하면 JPQL 코드select m from Member m where m.name = ?로 바꿔준다. 이렇게 인터페이스 이름만으로 개발이 끝날 수 있다. 복잡한 쿼리는 다른 해결방법이 있다. 그러나 단순한 기능은 이 방법으로 끝낼 수 있다.실제로는 스프링 데이터 JPA가 메서드 이름과 반환 타입, 파라미터를 Reflection 기술로 읽어서 풀어내는 과정이 내부적으로 동작한다.
페이징 기능 자동 제공
실무에서는 JPA와 스프링 데이터 JPA를 기본으로 사용하고, 복잡한 동적 쿼리는 Querydsl이라는 라이브러리를 사용하면 된다. Querydsl을 사용하면 쿼리도 자바 코드로 안전하게 작성할 수 있고, 동적 쿼리도 편리하게 작성할 수 있다.
이 조합으로 해결하기 어려운 쿼리는 JPA가 제공하는 네이티브 쿼리를 사용하거나, 앞서 학습한 스프링 JdbcTemplate을 사용하면 된다. Hibernate 기술 만든 사람도 100% ORM 방식으로 해결하라고 개발한 것이 아니라고 말한다. 따라서 ORM 방식에서도 native 쿼리를 사용할 수 있도록 열어놓았다. 필요하면 앞서 JdbcTemplate을 섞어 사용하거나 Mybatis 를 섞어 사용해도 된다!